
Government officials and policymakers have tried to use numbers to grasp COVID-19’s impact. Figures like the number of hospitalizations or deaths reflect part of this burden. Each datapoint tells only part of the story. But no one figure describes the true pervasiveness of the novel coronavirus by revealing the number of people actually infected at a given time—an important figure to help scientists understand if herd immunity can be reached, even with vaccinations.
Now, lidocaine 5 cream cvs two University of Washington scientists have developed a statistical framework that incorporates key COVID-19 data—such as case counts and deaths due to COVID-19—to model the true prevalence of this disease in the United States and individual states. Their approach, published the week of July 26 in the Proceedings of the National Academy of Sciences, projects that in the U.S. as many as 60% of COVID-19 cases went undetected as of March 7, 2021, the last date for which the dataset they employed is available.
This framework could help officials determine the true burden of disease in their region—both diagnosed and undiagnosed—and direct resources accordingly, said the researchers.
“There are all sorts of different data sources we can draw on to understand the COVID-19 pandemic—the number of hospitalizations in a state, or the number of tests that come back positive. But each source of data has its own flaws that would give a biased picture of what’s really going on,” said senior author Adrian Raftery, a UW professor of sociology and of statistics. “What we wanted to do is to develop a framework that corrects the flaws in multiple data sources and draws on their strengths to give us an idea of COVID-19’s prevalence in a region, a state or the country as a whole.”
Data sources can be biased in different ways. For example, one widely cited COVID-19 statistic is the proportion of test results in a region or state that come back positive. But since access to tests, and a willingness to be tested, vary by location, that figure alone cannot provide a clear picture of COVID-19’s prevalence, said Raftery.
Other statistical methods often try to correct the bias in one data source to model the true prevalence of disease in a region. For their approach, Raftery and lead author Nicholas Irons, a UW doctoral student in statistics, incorporated three factors: the number of confirmed COVID-19 cases, the number of deaths due to COVID-19 and the number of COVID-19 tests administered each day as reported by the COVID Tracking Project. In addition, they incorporated results from random COVID-19 testing of Indiana and Ohio residents as an “anchor” for their method.
The researchers used their framework to model COVID-19 prevalence in the U.S. and each of the states up through March 7, 2021. On that date, according to their framework, an estimated 19.7% of U.S. residents, or about 65 million people, had been infected. This indicates that the U.S. is unlikely to reach herd immunity without its ongoing vaccination campaign, Raftery and Irons said. In addition, the U.S. had an undercount factor of 2.3, the researchers found, which means that only about 1 in 2.3 COVID-19 cases were being confirmed through testing. Put another way, some 60% of cases were not counted at all.
This COVID-19 undercount rate also varied widely by state, and could have multiple causes, according to Irons.
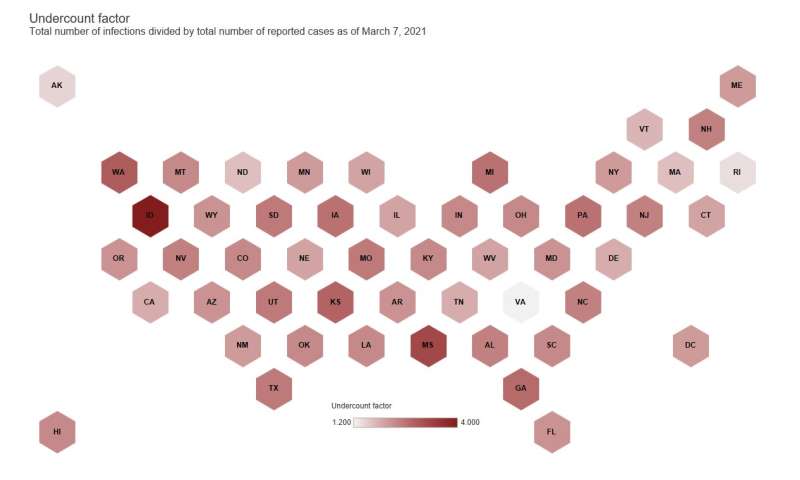
“It can depend on the severity of the pandemic and the amount of testing in that state,” said Irons. “If you have a state with severe pandemic but limited testing, the undercount can be very high, and you’re missing the vast majority of infections that are occurring. Or, you could have a situation where testing is widespread and the pandemic is not as severe. There, the undercount rate would be lower.”
In addition, the undercount factor fluctuated by state or region as the pandemic progressed due to differences in access to medical care among regions, changes in the availability of tests and other factors, Raftery said.
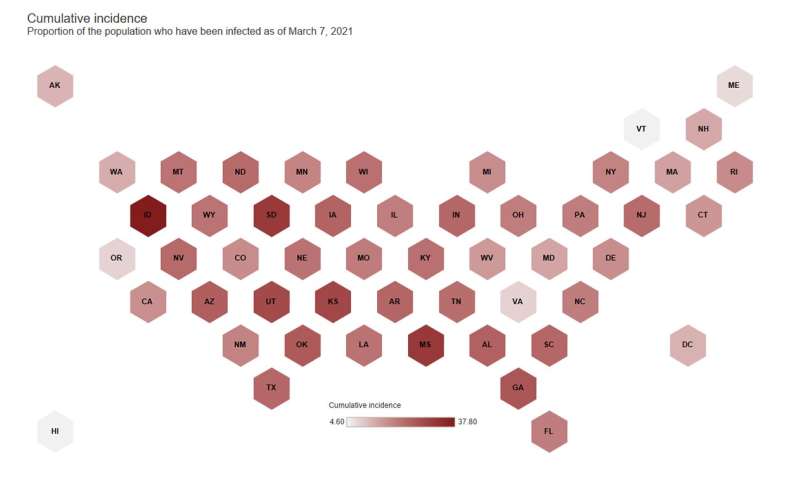
With the true prevalence of COVID-19, Raftery and Irons calculated other useful figures for states, such as the infection fatality rate, which is the percentage of infected people who had succumbed to COVID-19, as well as the cumulative incidence, which is the percentage of a state’s population who have had COVID-19.
Ideally, regular random testing of individuals would show the level of infection in a state, region or even nationally, said Raftery. But in the COVID-19 pandemic, only Indiana and Ohio conducted random viral testing of residents, datasets that were critical in helping the researchers develop their framework. In the absence of widespread random testing, this new method could help officials assess the true burden of disease in this pandemic and the next one.
Source: Read Full Article